
Recently at a conference, I had the privilege of demonstrating MemSQL processing over a trillion rows per second on the latest Intel Skylake servers.
.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")
Recently at a conference, I had the privilege of demonstrating MemSQL processing over a trillion rows per second on the latest Intel Skylake servers.
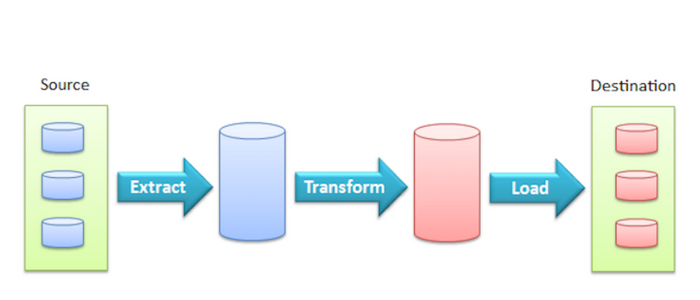
One might surmise that data "analysis" is, first and foremost, about data "access." It goes without saying that someone in the analyst's role must first obtain access to the data they wish to analyze. And with data being spread all over the inside, and now outside, of the enterprise (think of both your on-premises data stores, plus all the cloud and SaaS vendors you're currently using) modern day analysts face deeper challanges than ever before in obtaining access to the data they need.
And of course, techno-philosophical concepts like "democratizing acess to data" do nothing at all to help one overcome any of the actual technical integration challenges required to practically enable such unfettered access to one's data.
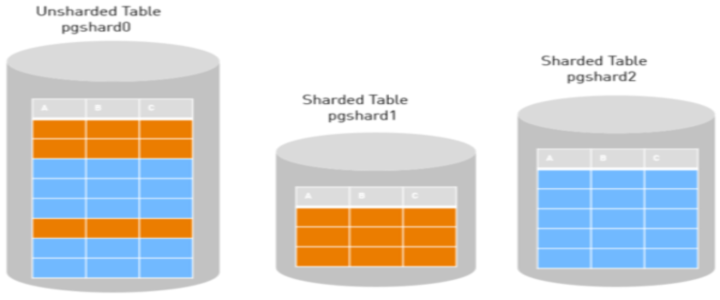
What do you do when you find yourself in a situation where you need to scale out your RDBMS to support greater data volumes than you originally anticipated? Traditionally, one would either need to vertically scale their infrastructure by putting their database on more powerful (costlier) machines or sharding their data across multiple workers.

A re-wording of one of the key maxims for startup success could be "KISS" - "keep it simple, stupid." If you've ever run your own startup, you also know the mantras of "focus" and "fail fast," and the critical reminder of how your product should be a "pain-killer not a vitamin."