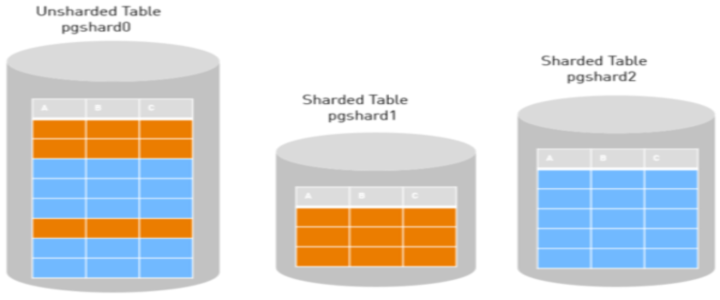
Whether you love or hate their paywall, the Times successfully balances competeing business frictions using a deep view of data.
Since our initial DataEngConf in 2015, The New York Times has been a key supporter of the conference. The very first ever DataEngConf talk was a keynote given by Chris Wiggins, the Times' Chief Data Scientist, who presented a broad yet fascinating perspective on "Data Science at The New York Times" (video here).
In the years since, we've had deeply technical talks from both data engineers and data scientists at the Times, and I'm excited that their involvement in DataEngConf this year is as large as it's ever been.