.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")

Read More

What if developers could ditch their No-SQL solutions and still get scalability from a more traditional relational datastore?
I've been noticing an interesting pattern recently where developers seem to be rejecting some of the newer, more en vogue data stores with limited functionality and use-cases (while promising easier scale) and returning to the comfortable tried-and-true paradigm of relational databases. It seems that we've hit a watershed point where developers finally believe they don't necessarily need to make a trade-off between database features on one hand and easy scalability on the other.
One such company enabling this return to the golden era of of RDBMS is Citus Data. Citus is blazing a trail in 'cloud-proofing' the gold standard of relational databases, PostgreSQL, through extensions that allow their customers to achieve much easier horizontal scalability than ever before.

In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with PipelineAI, a startup helping you to continuously train, optimize and host deep learning models at scale.

In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with Instrumental, an early-stage company building data systems to monitor and improve manufacturing line performance.

In this blog series leading up to our SF18 conference, we invite our featured startups to tell us more about their data engineering challenges. Today, we speak with Pachyderm, an early-stage company building a data platform for data science.
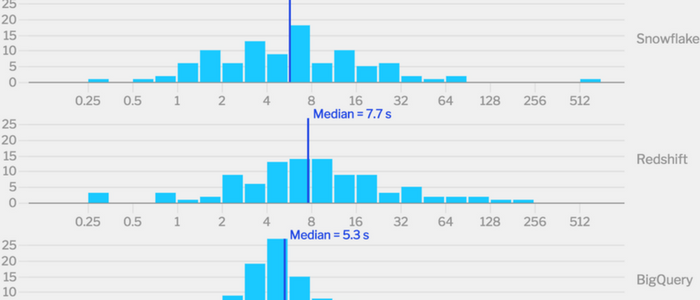
Fivetran is a data pipeline that syncs data from apps, databases and file stores into our customers’ data warehouses. The question we get asked most often is “what data warehouse should I choose?” In order to better answer this question, we’ve performed a benchmark comparing the speed and cost of three of the most popular data warehouses — Amazon Redshift, Google BigQuery, and Snowflake.

Batch data processing — historically known as ETL — is extremely challenging. It’s time-consuming, brittle, and often unrewarding. Not only that, it’s hard to operate, evolve, and troubleshoot.
In this post, we’ll explore how applying the functional programming paradigm to data engineering can bring a lot of clarity to the process. This post distills fragments of wisdom accumulated while working at Yahoo, Facebook, Airbnb and Lyft, with the perspective of well over a decade of data warehousing and data engineering experience.
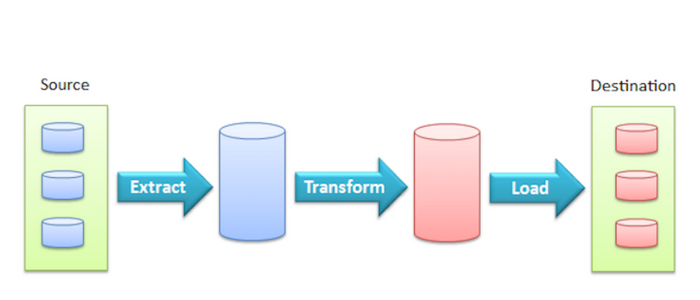
No one is happy with fragile ETL pipelines. But it doesn't need to be that way.
One might surmise that data "analysis" is, first and foremost, about data "access." It goes without saying that someone in the analyst's role must first obtain access to the data they wish to analyze. And with data being spread all over the inside, and now outside, of the enterprise (think of both your on-premises data stores, plus all the cloud and SaaS vendors you're currently using) modern day analysts face deeper challanges than ever before in obtaining access to the data they need.
And of course, techno-philosophical concepts like "democratizing acess to data" do nothing at all to help one overcome any of the actual technical integration challenges required to practically enable such unfettered access to one's data.

The past few years have been an interesting time for data science everywhere, and the media in particular! We’ve seen some incredible new technologies emerge, like open-source machine learning platforms, as well as machine learning services. These developments have opened the door for new consumer products, like conversational AIs, and new technologies in the media and advertising industries.

