.png?width=347&height=97&name=Data%20Council%20AI%20logo%20(1).png "Data Council")
Orchest is an open-source tool for creating data science pipelines. Its core value proposition is to make it easy to combine notebooks and scripts with a visual pipeline editor (“build”); to make your notebooks executable (“run”); and to facilitate experiments (“discover”).
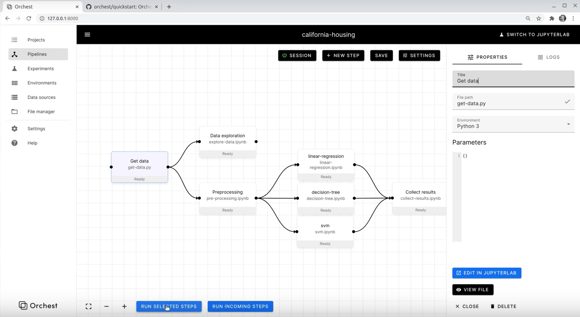
None of this requires any knowledge of cloud infrastructure, while still letting users take advantage of the cloud to develop, train and run their machine learning models. That is, if they want to: Orchest can also be used locally by those who’d rather not store their data in the cloud.
One of its interesting use cases is the possibility to write code using JupyterLab, thanks to a deep integration with the latter. With that in mind, Orchest is likely to appeal to data scientists who spend a lot of time in notebooks and don’t want to spend time on engineering-related tasks as part of their workflows.
It also positions itself as a simpler option compared to Airflow or Kubeflow. “You should be able to get Orchest up and running in about 10 minutes,” the team stated, pointing to https://github.com/orchest/orchest#installation for install instructions. But that’s just the start: Orchest also supports advanced uses such as distributed GPU-based deep learning.
You can find a video walkthrough of Orchest here. Also note that a managed cloud version is coming soon - you can join the waitlist by filling this form.